
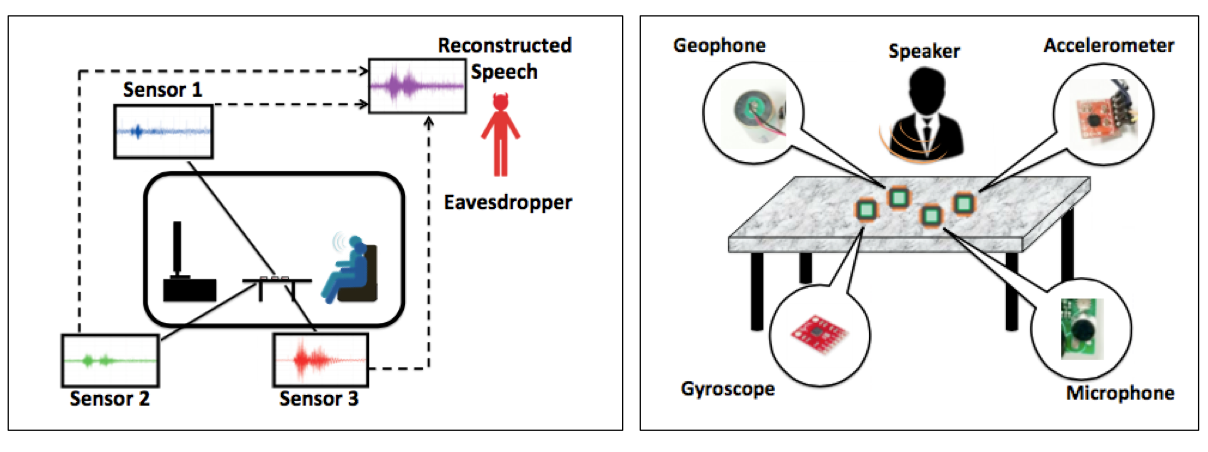
PitchIn: Eavesdropping via Intelligible Speech Reconstruction using Non-Acoustic Sensor Fusion
Wide deployment of activity sensors in mobile devices (e.g., smartphones, tablets, smart TV remotes, gaming controllers) and environmental/structural sensors in smart buildings and cities opens up opportunities for intelligent attacks. We find that an attacker may be able to leverage a network of sensors to launch an eavesdropping attack. Specifically, we investigate the feasibility of leveraging a network of non-acoustic sensors (e.g., geophone, accelerometer, or gyroscope) to reconstruct intelligible speech signals. However, the main challenge involved is unlike acoustic sensors that sample at high sampling frequency (> 5 KHz), typical applications using non-acoustic sensors sample at much lower frequencies. To address this challenge, we make use of distributed form of Time-Interleaved Analog-to-Digital Conversion (TI-ADC) to approximate an overall high sampling frequency, while maintaining low per-node sampling frequency. Hence we reconstruct an intelligible speech signal from a fusion of non-acoustic sensory data across networked devices.
Demo Video Clips
Demo 1: Individual non-acoustic sensors (without any fusion) are already responsive to human speech. However, signals are only intelligible when sampled at a high sampling rate. Following are four recordings of the same word sampled at 1, 2, 4, and 8 KHz, respectively. Try to guess what the word is after listening to the recordings. (Hint: It is the name of a company.)
|
Single geophone sampled at 1 KHz. |
Single geophone sampled at 2 KHz. |
|
Single geophone sampled at 4 KHz. |
Single geophone sampled at 8 KHz. |
Demo 2: Fused non-acoustic sensors using PitchIn attack increase the overall sampling rate of the reconstructed signal.
Following are three recordings of the same word reconstructed by fusing 2, 4, and 8 nodes, when sampling at 1 KHz each, yielding an overall sampling rates of 2, 4, and 8 KHz, respectively.
Try to guess what the word is after listening to the recordings. Hint: It is a number.
|
Two geophones each sampled at 1 KHz. |
Four geophones each sampled at 1 KHz. |
Eight geophones each sampled at 1 KHz. |
More Demo Video and Audio Clips
Several video/audio clips corresponding to the experimental results in the paper are available in a shared Google Drive folder. The clips demonstrate spectrogram reconstructions of the spoken word "apple" using the open source audio editor Audacity.
Related Publications
Acknowledgements
This project is partially supported by the National Science Foundation under grant CNS-1645759. The views and conclusions contained in print and online are those of the authors and should not be interpreted as necessarily representing the official policies or endorsements, either express or implied, of CMU, NSF, or the U.S. Government or any of its agencies.